MySQL 的回表查询与索引覆盖
聚簇索引与非聚簇索引
假如我们有这样一个表,建表语句如下:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(32) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned NOT NULL COMMENT '年龄',
`gender` tinyint(3) unsigned NOT NULL COMMENT '性别:1男,0女',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
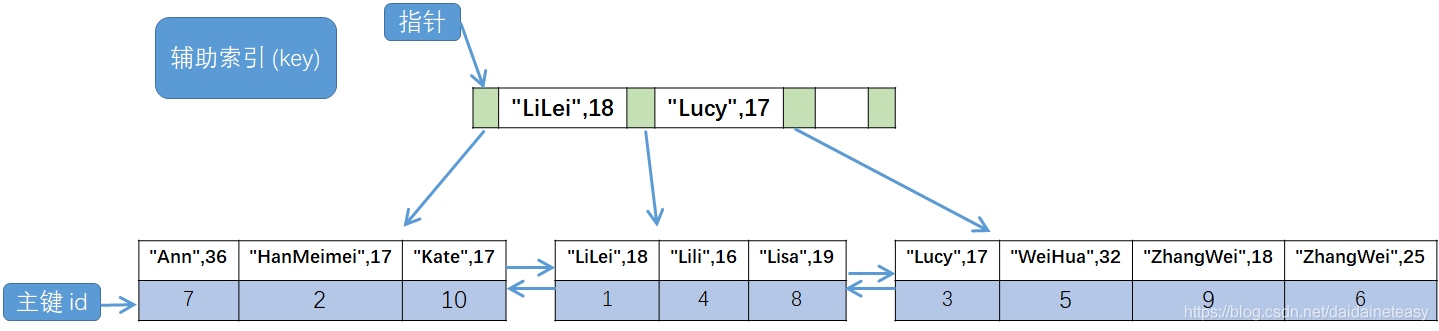
表中有两个索引,一个是主键索引 id,一个是普通索引 (name,age),根据前边介绍的聚簇索引和辅助索引的定义,这里主键索引就是聚簇索引,普通索引就是我们的辅助索引。
两棵索引树的示意图如下:

回表查询是什么?
回表查询(Lookup)是数据库查询过程中的一种操作,用于在索引中找到符合查询条件的行,并进一步通过主键或聚簇索引获取相应的数据行。
当执行一个查询时,数据库管理系统首先检查是否存在适用的索引来加速查询。如果存在合适的索引,数据库系统将使用索引来定位满足查询条件的行。然而,索引通常只包含部分列的值,而非整个数据行。因此,如果查询的结果需要返回完整的数据行,而不仅仅是索引中的列,就需要进行回表查询。
在回表查询过程中,数据库系统使用索引中的值来定位数据行的物理位置,进而通过主键或聚簇索引的指针访问磁盘上的相应数据页,并获取完整的数据行。这个额外的步骤称为回表(Lookup),因为数据库需要根据索引中的值“回到”表中获取完整的数据。
总之,回表查询是指在索引查询过程中,为了获取完整的数据行而进一步通过主键或聚簇索引进行访问的操作。
回表查询的开销取决于数据行的大小和磁盘访问次数。如果需要进行大量的回表查询,可能会导致额外的磁盘 I/O 操作和延迟,从而影响查询性能。为了减少回表查询的开销,通常会考虑使用覆盖索引(Covering Index)或者调整查询和索引设计,以尽量满足查询条件而避免回表操作。
假如我们需要查询姓名为 Lucy 的用户信息
select * from t_user where name = 'Lucy';

会先通过 (name,age) 这课索引树找到主键 id(这里是 3),再根据 id = 3,回到主键索引树中,找到对应的行数据信息("Lucy",17,0),这个过程,就叫做 “回表查询”。通过执行计划,也能看到使用了辅助索引 idx_name。
explain select * from t_user where name = 'Lucy';
举例来说,如果在一棵高度为 3 的辅助索引树中查找数据,那需要对这棵辅助索引树遍历 3 次找到指定主键,如果聚集索引树的高度同样为 3,那么还需要对聚集索引树进行 3 次查找,最终找到一个完整的行数据所在的页,因此一共需要 6 次逻辑 IO 访问以得到最终的一个数据页。

索引覆盖又是什么?
从上边我们知道了,通过辅助索引查询数据时,需要回到聚簇索引再扫描一遍,也就是需要 “回表查询” 。那有没有不需要回表查询的情况呢?
InnoDB 存储引擎支持 “索引覆盖” (也叫做 “覆盖索引” ),即 从索引中就可以得到查询结果,从而不需要查询聚簇索引中的行数据信息。(再次默念:索引即数据、数据即索引)
索引覆盖可以带来很多的好处:
- 辅助索引不包含行数据的所有信息,故其大小远小于聚簇索引,因此可以减少大量的 IO 操作。
- 索引覆盖只需要扫描一次索引树,不需要回表扫描聚簇索引树,所以性能比回表查询要高。
- 索引中列值是按顺序存储的,索引覆盖能避免范围查询回表带来的大量随机 IO 操作。
判断一条语句是否用到索引覆盖
索引覆盖有这么多的好处,那平常开发中,我们怎么知道语句是否用到了索引覆盖呢?
我们来看下这条语句的执行计划
EXPLAIN select * from t_user where name = 'Lucy';

对这条语句做下修改,再来看下执行计划:
EXPLAIN select id,name from t_user where name = 'Lucy';

执行计划中有了变化啊,最后一列 Extra 中多了 Using index 。而这里 Using index 就表示使用到了索引,并且所取的数据完全在索引中就能拿到,也就是用到了索引覆盖。
这也容易理解,我们修改语句后,需要查询的只有 id 和 name ,而这俩字段在我们的辅助索引 (name,age) 树中都有,name 就是索引键值的一部分,而 id 保存在叶子节点中,所以也就不需要再回表查询了。
会用到索引覆盖的 SQL 示例
牢记!!索引即数据,数据即索引。例如上面的那张表中的联合索引:(name,age),那使用到了这个联合索引就能直接取得三个值 id,name,age 因为,联合索引也是非聚集索引,它指向的是聚集索引,所以它们对于查询 SELECT name, age, id 这三个字段就无需取得一整行数据,只需索引就行了(因此避免使用 * 也就是这个原因!!)
我们来看下这些例子
EXPLAIN select id,name,age from t_user where name = 'Lucy';
EXPLAIN select id,name,age from t_user where name = 'Lucy' and age = 17;
EXPLAIN select count(*) from t_user where name = 'Lucy';
这三条语句应该不难分析,name 就是索引键值的一部分,符合最左匹配原则,并且想要查询的数据从索引树中就能拿到。所以用到了索引覆盖。
EXPLAIN select id,name,age from t_user where age = 17;
EXPLAIN select count(*) from t_user ;
上边这两条语句,也用到了索引覆盖。
WHAT ?有同学可能就发现问题了,不对吧?第一条语句查询条件 where age = 17 不符合最左匹配原则,没办法使用索引啊。第二条语句都没有查询条件,也没办法使用索引啊。
先来看下执行计划。


通过执行计划,我们会发现它们的 possible_keys 这列都没有值。
执行计划中,possible_keys 这一列表示的是可能用到的索引,而我们之前截图中,这一列中都是有值的。但 key 这一列中都有值 idx_name, 并且 Extra 中也都有 Using index ,说明用到了索引覆盖。
真实原因是这样的。
MySQL 优化器分析发现,查询语句无法使用到索引,只能通过全表扫描了。
不过还发现一点,不管是只扫描聚簇索引对应的表,还是只扫描辅助索引对应的表,最终都能得到查询结果。而 辅助索引对应的表远小于聚簇索引对应的表,这样就可以减少 IO 操作,所以优化器就选择了全表扫描辅助索引对应的表,也就用到了索引覆盖。
回顾一下这个表
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(32) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned NOT NULL COMMENT '年龄',
`gender` tinyint(3) unsigned NOT NULL COMMENT '性别:1男,0女',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
该表定义了一个名为 idx_name 的复合索引,包含了 name 和 age 两个列(同时非聚簇索引指向的是聚簇索引)。在执行 COUNT(*) 查询时,数据库优化器可以利用这个复合索引来快速计算结果。
复合索引 idx_name 包含了查询所需的所有列,因此可以直接通过索引来获取数据行的计数,而无需进一步访问数据页获取完整的数据行。这种情况下,查询只需要扫描索引而不需要回表操作,从而实现了索引覆盖。
再提醒一遍!!索引即数据,数据即索引。
再继续来看下边这两条语句。先来说下结论,这两条也用到了索引覆盖。
EXPLAIN select id from t_user where id = '3';
EXPLAIN select count(*) from t_user where id = '3';
看下执行计划


这两条语句都是通过 id 来进行查询,所以会用到主键索引,但是为什么也会用到索引覆盖呢?它们已经不需要回表了呀?
做出回答前,我们先再来看一条 SQL 执行计划
EXPLAIN select name from t_user where id = '3';

这条语句跟前边的差别只在于,前边只查询了 id,而这里只查询了 name 。执行计划中就看到,这条查询 name 的语句就没有用到索引覆盖。
我们再来体会一下:“索引覆盖” 指的是,从索引中就可以得到查询结果,从而不需要查询聚簇索引中的行数据信息。
也就是说,如果只查询 'id' 的话,从聚簇索引中就能得到结果,最终也不需要再查询行数据信息,也就是用到了索引覆盖。同样的,count(*) 也是这样的原理。
总结(避免 *)
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。
但是为了避免回表查询,尽量使用到索引覆盖,不应该使用 * 来全表查询!!